
Start by giving a short description of what web scraping is. Web scraping is a powerful method that is at the heart of the digital age. It is based on taking data from websites and automating the process of getting information. Web scraping is a way for organizations and people to collect valuable data sets for things like market research and academic research.
Choosing the best programming language for web scraping is a very important choice in the world of web scraping. The language chosen for a job can have a big effect on how quickly, effectively, and easily it can be done. It affects how data is received, parsed, and used, so it is an important thing to think about when web scraping.
In this piece, we’ll go on a journey to learn about different programming languages and how well they work for web scraping. Each language has its own skills, libraries, and traits that make it a good fit for certain scraping needs. Our goal in doing this research is to give readers the information and insights they need to choose the top coding language for their web scraping projects.
Top Coding Language for Web Scraping
Choosing the right computer language can make all the difference between a smooth and quick data extraction process and one that is difficult and takes a lot of time. When it comes to web scraping, the many different computer languages offer a wide range of tools and abilities, each with its own pros and cons.
We will look at what makes each of these languages stand out, from Python’s flexibility to JavaScript’s ability to handle changing content and Java’s strength in enterprise-level scraping. Come along with us as we find the best coding partners for your web scraping experiences.
Python
When it comes to web scraping, you can use a number of different computer languages. Python is one of the most well-known and useful choices. Python is a popular choice among people who like to scrape the web because it has a lot of benefits. Let’s look at what makes Python stand out when it comes to web scraping.

Advantages of using Python for web scraping
Python has a lot of great features that make it a great choice for scraping the web. Among these benefits are:
Versatility: Python’s flexibility lets you use it for a wide range of web scraping projects, from easy data extraction to complex web crawling and automation. Python can help you scrape e-commerce sites for information about products or get information from news sites.
Abundant Libraries and Frameworks: Python is good at web scraping because it has a lot of tools and frameworks made for that purpose. BeautifulSoup and Scrapy are two choices that stand out.
BeautifulSoup: This library makes it easier to parse HTML and XML documents, which makes it easier to move around and get info. Its code is easy to understand, so even people who have never done web scraping before can quickly learn the basics.
Scrapy: Scrapy is a powerful system that gives you a structured way to build web spiders for bigger web scraping projects. It has features like automatic request handling, strong data storage, and asynchronous scraping, which makes it a good choice for collecting large amounts of data.
Ease of Learning: Python’s syntax is easy to read and understand, so both new and expert programmers can use it. If you’re new to web scraping, the fact that Python is easy to learn is a big plus.
Large Community and Documentation: Python is used by a lot of people, so there are a lot of online tools and documentation for it. When you’re learning how to web scrape and run into problems, you can get help from boards, tutorials, and the community.
Cross-Platform Compatibility: Python is cross-platform, which means that your web scraping code will run smoothly on Windows, macOS, and Linux, among others.
Libraries and frameworks
As was already said, Python is good at web scraping because it has a large number of tools and frameworks. Here, we’ll look at two of the most popular tools:
BeautifulSoup: For web scraping, this tool is a real gem. It does a great job of parsing and browsing HTML and XML documents, making it easy to extract data. Its name is a good indication of how it can clean up the structure of web pages.
Scrapy: Scrapy is the tool to use if your web scraping project needs to be more organized and scalable. It has everything you need to build web spiders, automate the crawling process, and store scraped data effectively.
Code Examples
To get started with web scraping in Python, let’s explore a couple of code examples:
Example 1 – Web Page Parsing with BeautifulSoup:
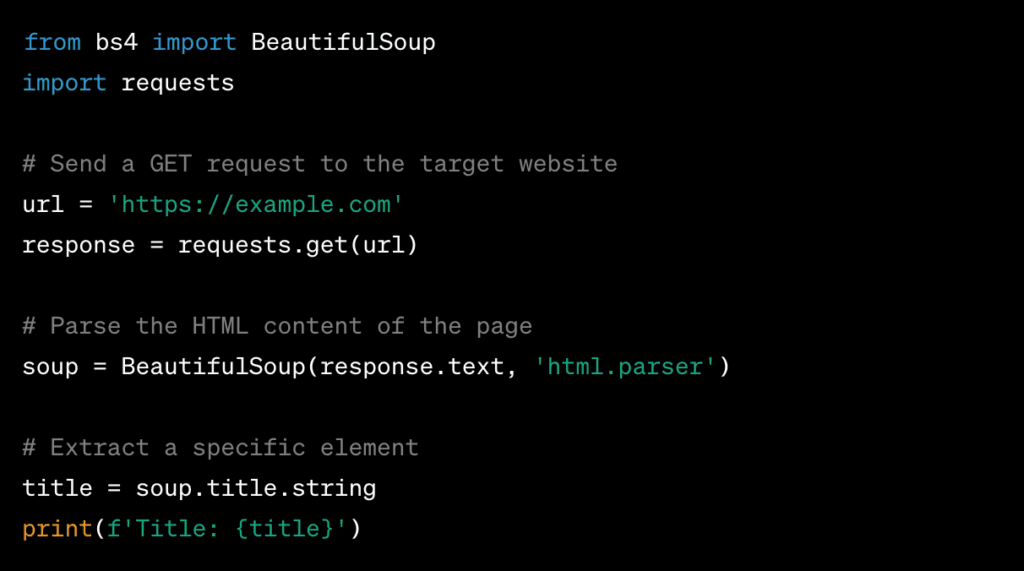
Example 2 – Creating a Spider with Scrapy:
To use Scrapy for web scraping, you’ll need to set up a Scrapy project and define a spider. Here’s a simplified example:
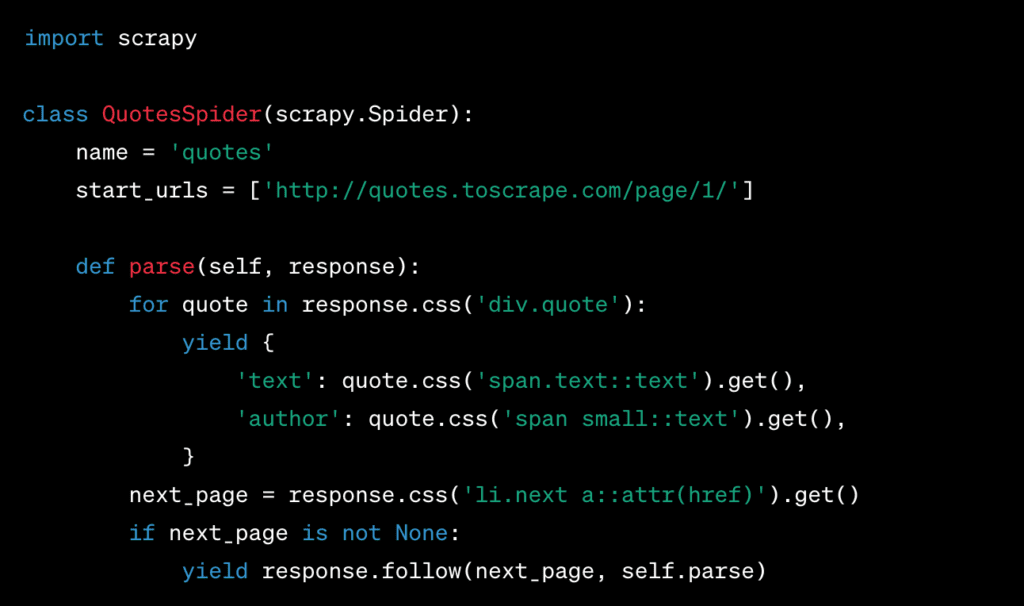
In this Scrapy example, we make a spider that takes quotes from a website and scrapes multiple pages by following the pagination links.
These bits of code are just a taste of what you can do with Python to scrape the web. If you have the right tools, frameworks, and tutorials, you’ll be ready to start your web scraping journey.
JavaScript
JavaScript is an important part of web scraping because it takes a different method than other programming languages. In this part, we’ll talk about how important JavaScript is for web scraping, its pros and cons, the libraries and tools you can use, and give you some code examples and how-tos.
JavaScript’s Role in Web Scraping
Most people know JavaScript as a client-side coding language used to make the web more interactive. But it is also a useful tool for web scraping, especially when dealing with websites that use JavaScript to load a lot of dynamic material. Here are some of the most important things that JavaScript does for web scraping:
Dynamic Content Handling: JavaScript is used by many modern websites to load information on the fly. This means that the HTML source may not have the information you want to scrape. With JavaScript, you can interact with a webpage, make events happen, and get info as it loads.
Browser Automation: JavaScript can be used to make a web browser do things automatically, like click buttons, fill out forms, and move. This is a must-have skill for exploring websites with a lot of interactive parts.
Headless Browsing: Headless viewing is made easier by JavaScript, which lets you run a web browser in the background without a graphical user interface. This works well for web scraping because it uses fewer resources.
Pros and Cons of Using JavaScript for Web Scraping
JavaScript has both pros and cons when it comes to web scraping:
Pros:
Handling Dynamic Content: JavaScript is great at dealing with websites that have content that changes all the time. This makes it a good choice for scraping data from pages that load information using AJAX calls.
Interactive Websites: When scraping interactive websites, you can act like a user to get to the data you want with the help of JavaScript.
Cross-Browser Compatibility: JavaScript-based tools can be used in different browsers, which makes them useful for a wide range of scraping jobs.
Cons:
Complexity: Web scraping with JavaScript can be harder than traditional HTML parsing because you have to deal with asynchronous processes and dynamic rendering.
Rendering Time: JavaScript scraping could take longer because pages have to be rendered in a browser without a head. This could slow down the scraping process.
Detection Risk: Some websites have anti-scraping measures that can find automated JavaScript activities, which is a risk for web scrapers.
Libraries and Tools (e.g., Puppeteer)
Puppeteer is a great tool for web scraping with JavaScript. Puppeteer is a Node.js library that lets you handle headless Chromium browsers with a high-level API. It makes it easier to scrape websites by:
Page Interaction: Puppeteer lets you move through pages, click on things, and fill out forms just like a real user would.
Page Screenshot: You can save PDFs or take pictures of web pages to look at them later.
Monitoring the network: Puppeteer has tools for keeping track of network calls, which can be useful when pulling data from APIs.
Code Examples
Here are two brief code examples to illustrate the use of JavaScript and Puppeteer for web scraping:
Example 1 – Web Page Screenshot with Puppeteer:
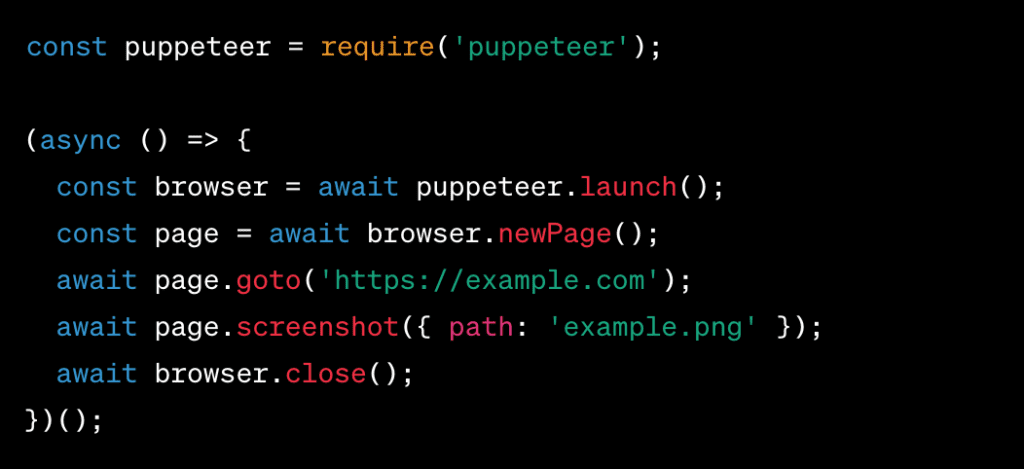
Example 2 – Scrape Dynamic Content with Puppeteer:
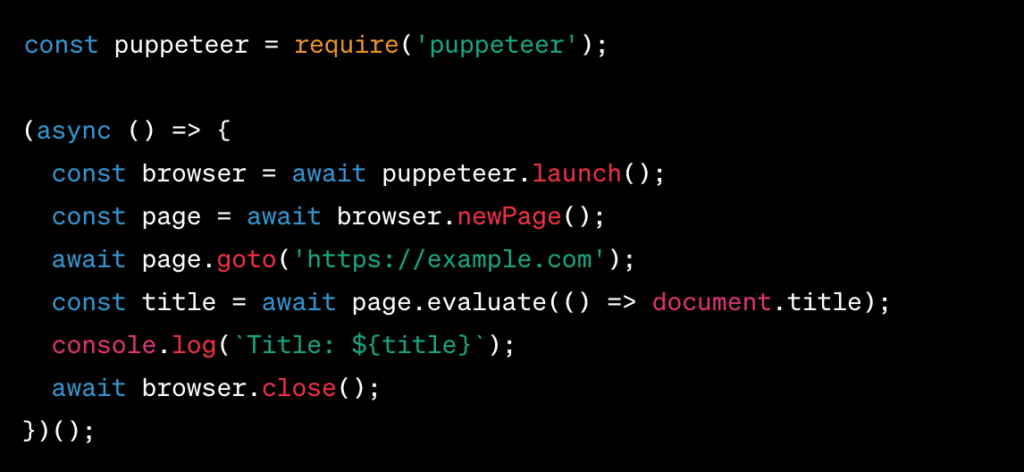
This code snippet shows how Puppeteer can be used to get dynamic information from a website, such as the page title.
In conclusion, JavaScript, especially when combined with libraries like Puppeteer, is a strong solution for web scraping, especially when working with dynamic and interactive web pages. For web scraping projects to go well, you need to know what it does, what its pros and cons are, and how it works.
Ruby in Web Scraping: A Powerful Choice
Ruby is a coding language that is often ignored but is very good for web scraping. In this part, we’ll talk about the benefits of using Ruby for web scraping, look at some of its most popular gems and libraries, and show how it works in this area with code examples and tutorials.
Benefits of Utilizing Ruby for Web Scraping
Ruby is a strong choice for web scraping fans because it has a number of appealing benefits:
Elegant and Readable Code: It is known for its clean and elegant style, which makes for code that is easy to read. This makes it easier to write and manage web scraping scripts and makes it easier to learn.
Rich Ecosystem of Gems: A lot of gems (Ruby tools) designed for web scraping have been made by the Ruby community. These gems make it easier to do things like parse HTML and handle HTTP calls when scraping.
Cross-Platform Compatibility: It means that your web scraping apps will run smoothly on Windows, macOS, and Linux, as well as other operating systems.
Dynamic Typing: Ruby’s dynamic typing system gives you a lot of freedom, so you can adapt to different data structures you find while scraping the web without having to make too many type statements.
Object-Oriented: This makes it easier to organize code into modules and classes that can be used again and again. This makes code easier to manage and scale.
Gems and Libraries for Ruby Web Scraping
Ruby is good at scraping the web because it has a large number of gems and tools. Nokogiri and Mechanize are two choices that stand out:
The Nokogiri
Nokogiri is a tool for Ruby that can read both HTML and XML. It is the best way to get organized data from web pages because of how powerful it is. With Nokogiri, it’s easy to move around in HTML and XML texts and change them.
Mechanize
Mechanize is another gem that makes it easier for Ruby users to connect with the web. It acts like a web browser and lets you navigate websites, fill out forms, and get info through code. Mechanize is especially helpful when it comes to websites that need users to log in.
Code Examples
Let’s explore some code examples to showcase Ruby’s effectiveness in web scraping:
Example 1 – Basic Web Scraping with Nokogiri:

This code demonstrates how to use Nokogiri to fetch a web page, parse its HTML content, and extract the page title and links.
Example 2 – Automated Web Interaction with Mechanize:
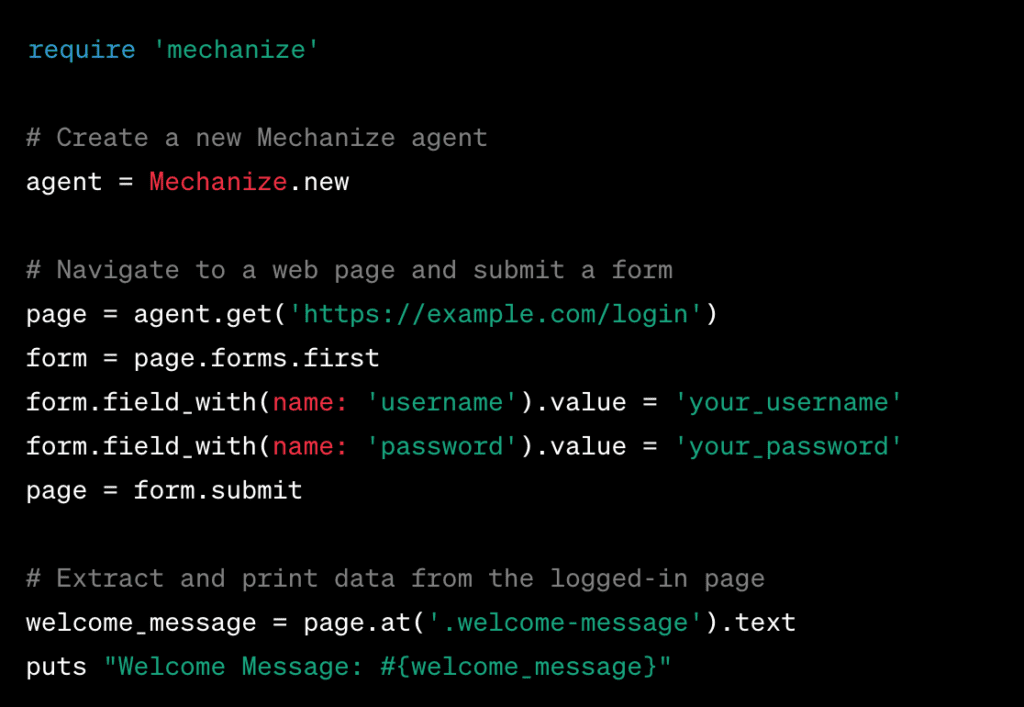
In this case, Mechanize is used to handle the process of logging into a website and getting information from the page after logging in.
Ruby is a good choice for web scraping because it is elegant, has strong tools like Nokogiri and Mechanize, and has a large and active community. These code examples and lessons show how Ruby can be used to gather information from the web in a useful way.
PHP: A Viable Choice for Web Scraping
PHP might not be the first language that comes to mind, but it has its good points and can be used for some scraping tasks. PHP is a server-side coding language that is often used for building websites. It has some special features that make it a good choice for web scraping projects.
Versatility in Web Scraping: PHP is useful for more than just making websites. It can also be used for web scraping. Developers can make good scraping scripts with it because it can interact with web pages, send HTTP requests, and read HTML text. This flexibility is especially helpful when pulling information from websites with simple layouts.
Familiarity and Accessibility: PHP is a language that is used a lot in web development, so many web developers already know how to use it. If you already know PHP, it’s not too hard to switch to web scraping jobs. This saves you time and effort in learning a new language.
Integration with Web Servers: Web scraping tools are easier to use because PHP works well with web servers like Apache and Nginx. This means that PHP scripts can run on web servers, be set to run at certain times, and be viewed through HTTP endpoints.
Libraries and Tools for PHP Web Scraping
Even though PHP doesn’t have as many libraries as Python, it still has tools and packages that are useful for web scraping. Goutte, a web scraping tool built on top of the Symfony HTTP client, is a popular choice.
Goutte
Goutte makes web scraping in PHP easier by giving you an API that makes it easy to move around and interact with web pages. It makes it easy to read HTML, submit forms, and handle HTTP requests. With Goutte, you can make scraping scripts that act like how a user would communicate with a web browser. This makes it useful for a wide range of scraping tasks.
Code Examples
Let’s explore a basic code example using Goutte for web scraping in PHP:

In this example, we use Goutte to get a web page, get the page’s title, and make a list of all its links.
Even though PHP might not be the best option for complicated web scraping projects, it is still a good choice for simple scraping tasks, especially for people who are already familiar with the language. Goutte and other PHP libraries can help make the process easier and give PHP writers access to web scraping.
Go (Golang): Efficiency and Concurrency
When it comes to web scraping, speed and parallelism are the most important things, especially for large-scale data extraction jobs. In this part, we’ll look at how Go (also called Golang) is great at these things, which makes it a great choice for web scraping. We will also look at how Go can handle multiple requests at the same time and show you some famous Go libraries and frameworks that are made for web scraping.
Go’s Efficiency in Web Scraping
Go is known for being efficient, which means that web scraping tasks can be done faster. Go code runs quickly because it has been built. This makes it a great choice for handling large amounts of data.
The language is simple and practical, which makes it easier to write code that is clear and to the point. This makes web scraping scripts more efficient. This speed is especially important when working with big data sets or scraping a lot of web pages at once.
Concurrency: Go’s Crown Jewel
One of the things that makes Go stand out is that it supports concurrency by default. This makes it a great choice for web scraping jobs that involve processing multiple requests at the same time. Go’s concurrency model is based on Goroutines and channels, which make it easy for developers to start multiple jobs at the same time without the hassle of traditional threading.
With Go, each web request or data extraction job can be run in its own Goroutine when web scraping. These lightweight threads can run at the same time, so the scraping process can make good use of the CPU cores it has. This means that Go can easily handle thousands of web calls at the same time, which speeds up data retrieval by a lot.
Handling Multiple Requests Concurrently
In the case of web scraping, it can make a big difference to be able to get and process data from various sources at the same time. This is made easy by Go’s Goroutines and channels. Here’s a simple example of how Go can handle multiple web requests at the same time:

In this example, multiple URLs are fetched concurrently, taking full advantage of Go’s concurrency features.
Popular Go Libraries and Frameworks for Web Scraping
Go has a number of tools and frameworks that make it easier to scrape the web:
- Colly: Colly is a powerful and easy-to-extend Go system for scraping. It has features like parallel scraping, controlling the rate of scraping, and automatically handling cookies.
- GoQuery: GoQuery is a tool that is built on top of Go’s net/html package. It lets you use syntax similar to jQuery to read and change HTML.
- Scrapy-Go: Scrapy-Go is a web scraping system that is based on Python’s Scrapy. It gives a structured way to build web spiders in Go.
Go is a great choice for web scraping jobs because it is fast, supports multiple processes at once, and has a growing ecosystem of libraries and frameworks. This is especially true when large amounts of data need to be extracted at the same time. It is a powerful language for web scraping fans and writers alike because it is easy to use and works well.
Read Related Blogs:
- Best Programming Languages for Backend Development
- Most Useful Programming Languages for Engineers
- Why Is It Important to Learn Programming for Cyber Security?
Factors to Consider When Choosing a Language for Web Scraping
Picking the right computer language for web scraping is a big decision that can have a big impact on how well and quickly you can get data from the web. To make a good choice, you need to carefully think about a number of important things.
These include the needs of your scraping project, the size and availability of the language’s community and support, the language’s learning curve, and the important legal and ethical issues that come up when dealing with web resources.
we’ll take a closer look at each of these aspects to help you figure out which computer language is best for your web scraping projects.
Project Requirements
In the world of web scraping, your project’s success depends on how well you match it to its unique needs. These needs can include a wide range of important factors, such as the amount of data you need to extract, the complexity of the websites you’re trying to reach, and any speed-related needs. By breaking down and handling each of these parts, you can make a plan for your web scraping project that is effective and fits your needs.
Data Volume
One of the most important things to think about is how much info you want to scrape. It tells you what equipment and facilities you’ll need. Whether you need to gather a small set of data or a huge amount of information for your project, your method must be scalable. Smaller datasets might be able to be handled with simple tools, but bigger ones need scraping systems that are more reliable and maybe even work in groups.
Complexity of Websites
Another important factor is how complicated the website is. Websites can be simple and well-organized, or they can be complicated and move around. It is important to know how your target websites are put together and how they work. Simple sites might only need simple parsing methods, while complex ones might need more advanced ones, like using headless browsers and complex parsing libraries.
Speed Requirements
For some tasks, speed requirements are very strict. Real-time data updates, retrieving information that needs to be done quickly, or frequent changes to a website may require fast data extraction. When this happens, it’s important to focus on computer languages and frameworks that are known for being fast and able to handle multiple tasks at once. When speed is the most important thing, it is important to optimize scraping scripts and reduce delay.
Community and Support: The Pillars of Successful Web Scraping
Availability of Resources and Documentation
A web scraping ecosystem that works well depends on having full tools and documentation. Strong instructions and tutorials give developers the help they need to solve problems and use scraping tools and libraries to their fullest potential. The strength of a language’s support infrastructure can be seen in how many code examples, forums, and public documents there are.
Active User Base
A coding or programming language or library can’t live without users who use and work with it. Web scraping tools are made, improved, and fixed by a group of users who are passionate about using them. These groups are great places for programmers to share ideas, solutions, and best practices. This makes it easier for developers to get help and work together to solve web scraping problems.
Legal and Ethical Considerations
Respecting Website Terms of Service
Web scraping that is done in an honest way starts with a basic rule: websites’ terms of service must be followed. These terms, which can often be found in the “Robots.txt” file of a website, set out rules and standards for web crawling and data extraction. Following these rules is not only the right thing to do but also a must if you want to have a good online reputation and stay out of trouble with the law.
Legal Implications of Web Scraping
Web scraping happens in a legal environment that changes from place to place and situation to situation. Web scraping is not illegal by itself, but it can be when it breaks rules about copyright, privacy, or security.
It is very important to understand the legal consequences and possible risks of web scraping. It takes careful attention to make sure that scraping stays within the law, which protects both your project and your image. A responsible and legal strategy for web scraping includes getting legal help and following the rules.
Best Practices for Web Scraping in Your Chosen Language
Handling HTML and Data Extraction
Web scraping works best when you know how to deal with HTML. Learn how web pages are put together and use libraries or tools for your chosen language to get accurate info. Use selectors or XPath to find the information you want and avoid parsing it more than once.
Managing Requests and Handling Errors
Managing HTTP requests is a key part of scraping that works well. Set up ways to handle rate limiting, timeouts, and retries to make sure the system is sturdy. Handling errors in a polite way is also important to deal with unexpected situations and keep scraping from stopping.
Parsing and Storing Data
After you get the data, you can put it into structured forms like JSON or CSV by parsing it. Set up the data in a way that makes it easy to analyze or store in systems. Keep data structures clear and efficient to speed up processes after scraping.
Throttling and Respecting Website Policies
Follow good scraping practices by putting in place ways to slow down requests. Respect website rules, like robots.txt, and don’t make computers too busy. Make ethical concerns a top priority to make sure that web scraping goes well and to keep the purity of your project.
Final Verdict
So, picking the best programming language for web scraping is not easy. Most of them work with CSS selectors, and they all have their own features and specialty libraries or frameworks that make them good for web scraping.
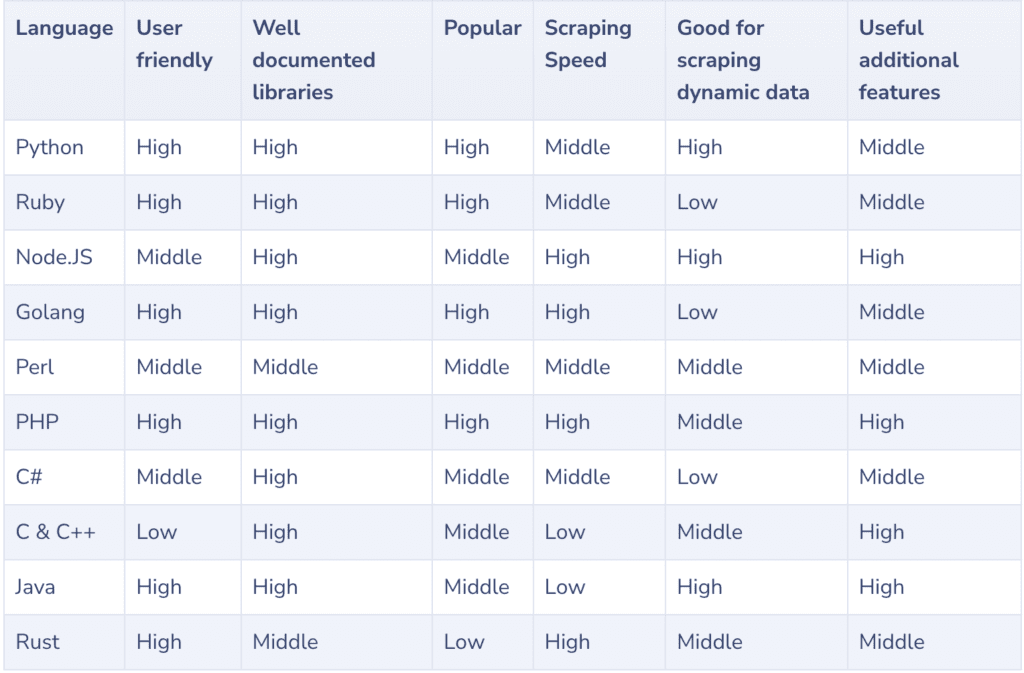
Image Credit: https://scrape-it.cloud/
No language by itself can be perfect. It will depend on what you want to do. Each language has pros and cons that you should think about carefully in light of your web scraping needs.
Once you know exactly what you want, the above descriptions of each language’s features and limits will help you a lot.
Keep in mind a website’s terms and conditions when you web scrape. Don’t put any of the scraped info on a public forum.
Learn these languages and choose the best one to pull data from the web and give yourself a huge advantage over others.